
各位同学,今天想为大家带来关于 FusionX 研发过程中的感想。在 FusionX 团队和其他项目组的共同努力下,FusionX 于去年底发布了第一个正式版本,很快 FusionX 就将在第一个商业项目上被正式使用。今天我想谈一下在设计和建设 FusionX 的过程中我们的思路和想法,以及对 FusionX 未来迭代和发展的期望。
什么是低代码?
在得到公司批准建设 FusionX 时,我们首先想要确定的问题就是「什么是低代码」。是的,这个问题看起来过于「小儿科」,但是理解低代码和低代码平台的定义对于我们希望把 FusionX 建设到何种程度——也就是能力边界在哪里,以及达到什么目标——来说是非常重要的。
我们先来看 Wikipedia 和 Forrester 给出的两个定义:
低代码开发平台(LCDP)提供了一种允许开发者以图形化界面(GUI)和配置式的方式快速开发应用程序的环境,而不完全通过编写代码实现交付。 —— Wikipedia
低代码开发平台(LCDP)提供了一快捷交付业务应用的能力,而不需要开发者编写太多的代码,也不需要了解常规开发中的前置工作,例如编程语言和开发环境的配置等。 —— Forrester
在这两个定义中,有一些共同点可以被我们提取出来,稍加总结如下:
- 图形化界面(GUI)
- 配置式(Configurable)
- 低门槛(Minimal upfront investment)
- 快速交付(Rapid delivery)
在 FusionX 的设计与开发过程中,项目团队的同事们始终将这四个特点所组成的定义作为我们低代码开发平台的出发点与落脚点。换句话说,FusionX 的目标就是通过图形化界面和配置式的开发方式,实现低门槛的快速交付。
FusionX 的构成
刚才我们讲到,FusionX 的开发方式是基于图形化界面和配置式的,这需要我们首先建设一个低代码的 「开发工具」;其次,FusionX 也需要考虑如何存储开发者建设的应用、以何种结构表示这些应用,以及最后:如何将存储的结构转变为用户可以正常使用并与之交互的「运行时」。
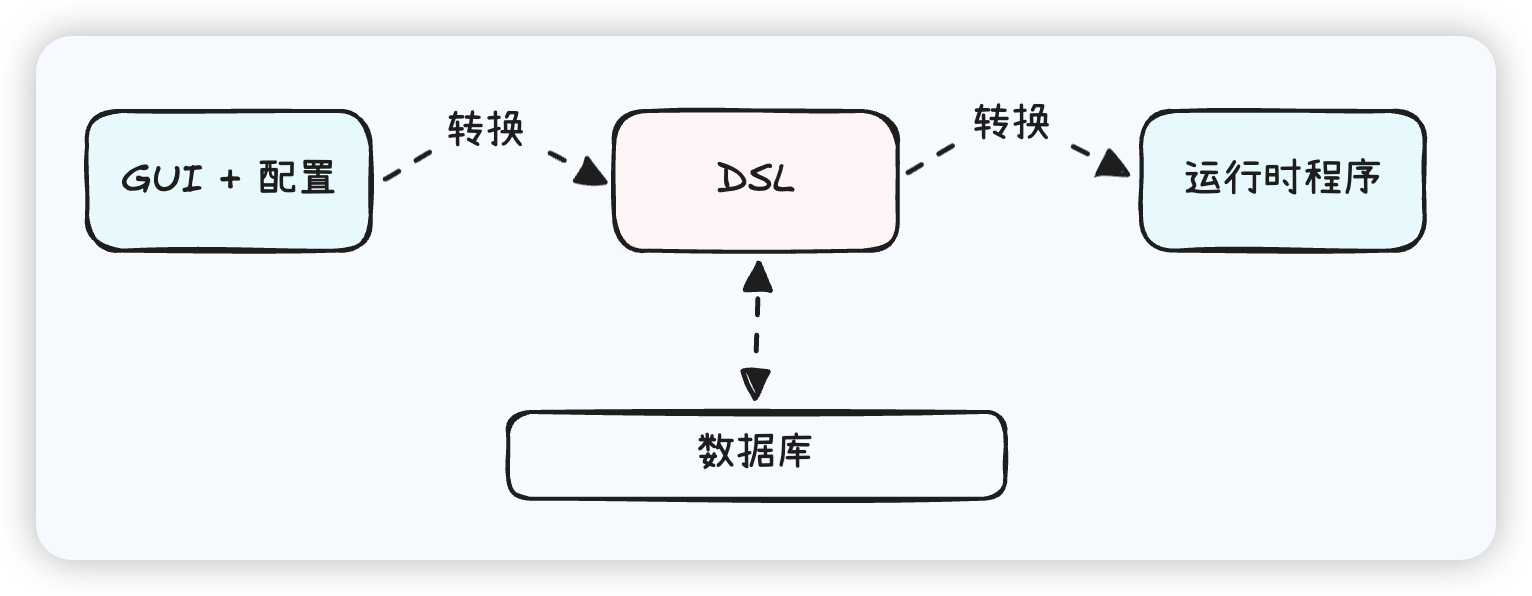
显然,这张图里最核心的位置,就是 DSL。换句话说,使用开发工具建设应用,或者在运行时执行应用,都需要依赖于中间的、用于存储应用的数据结构。当开发者使用开发工具建设应用时,他们需要通过 GUI 来配置应用的组件、行为和属性,这些配置信息最终会被转换为可以被轻松存储的数据结构;而当应用需要被运行时执行时,在运行时存储在数据库中、符合约定的数据结构的数据来创建应用的实例,并执行应用的行为。
在 FusionX 中,我们称这种用于存储应用数据的结构为「Schema」。
Schema
那么应当如何设计一个足以表示复杂应用程序的结构呢?我们不妨先看一下在一个应用中多有多少信息必须要被存储。
- 一个应用包含多个组件,每个组件有自己的行为和属性;
- 组件之间可能有依赖关系,例如一个组件的行为依赖于另一个组件的属性;
- 组件之间可能发生嵌套,即一个组件(如 Tab)包含了另一个或一些组件;
- 应用可能有自己的全局状态,例如用户登录信息等;
- 应用可能有关联的数据表;
- 应用可能有自己的生命周期,例如启动时需要初始化一些数据,关闭时需要清理资源等;
- 应用可能有一些用户定义的全局函数,可以被组件或生命周期调用;
- 如果应用含有流转程序,那么还应当有流程。
- ...
在设计 FusionX 的过程中,我们首先明确的就是这些信息。从某种意义上来说,这也是一份需求清单,告诉我们要为 FusionX 开发哪些在 pro code 开发场景下非常常见的功能,算是为我们后续的开发工作奠定了基础。
最终,正如大家知道的,我们采用 JSON 结构表示应用的 Schema。一个 Schema 看上去可能是这个样子的:
{
"version": "1", // 版本号,用于后续 schema 升级时的迁移策略
"dataSources": { // 数据源,包括数据库、API 等
"db": [], // 数据库表列表,每项包含数据库、表名等信息
"api": [], // API 列表,每项包含 API 名称、URL、请求方法、请求参数等信息
},
"functions": [ // 用户定义的全局函数
{
"name": "myFunction", // 用户定义的函数名称
"uid": "joa91a01kd86ns",
"desc": "", // 用户定义的函数备注
// 函数体,包含 FusionX 的 API
"body": "if ($values.age < 18) { $widgets.someField.setEnabled(false) }"
},
// ...
],
"states": { // 全局状态,可以在函数、自定义校验、组件 options 等场景下通过`$state.`获取
"user": {
"name": "admin",
"email": "admin@example.com",
"age": 30,
"dept": 1,
"role": [1, 101, 102]
},
// ...
},
"componentsTree": [ // 组件树
{
"uid": "dkf049pdk3f0hmhv", // 组件唯一标识,可以通过`$widgets.`获取组件
"type": "Input", // 组件类型,不同类型的组件有不同的行为和属性
"group": "form", // 组件所属的分组,用于在 GUI 中组织组件
"title": "输入框", // 组件在 GUI 中的标题
"props": { // 组件的属性,用于配置组件的行为和外观
"field": { // 表单组件特有属性
"name": "name", // 字段名,也可以通过`$widgets.`获取组件
"label": "姓名",
"required": true
},
"maxlength": 10,
"placeholder": "请输入姓名",
"events": {} // 组件的事件回调,可以绑定函数
}
},
// ...
],
}
当用户在低代码设计器中对应用进行设计时,其本质是对 Schema 结构的修改,即:
- 当用户新增组件时,体现为在 Schema 中插入新元素;
- 当用户修改组件的配置项时,体现为修改 Schema 中对应的元素中的某个属性;
- 当用户调整两个组件的顺序时,体现为修改 Schema 中对应的两个元素的下标;
- 当用户删除组件时,体现为从 Schema 中移除对应的元素;
- 当用户复制组件时,体现为从 Schema 中复制指定的元素并插入到该元素后方,同时重新生成组件的唯一标识 UID;
- ......
Schema 的结构并非只是一个存在于项目中的d.ts声明,而是由我们经过讨论并起草《低代码协议》后确定的。《低代码协议》定义了采用低代码的开发活动时涉及的概念、术语、接口等,并为我们提供了一份从工程学角度描述和解释我们工作的规范。
开发环境
刚才我们讲到,如果将 Schema 看做一门 DSL,那么开发环境就是用于编写和执行这种 DSL 的工具。它产生 Schema,可能还会像 linter 和 formatter 一样根据既定的规则和标准对 Schema 进行转换和调整,最重要的是,它需要能够执行 Schema,将其转换成浏览器可以执行的 JS、HTML 和 CSS。
在 FusionX 中,开发环境主要由编辑器和解释器组成,这对应了我们发布的 npm 包中@fusionx/editor和@fusionx/interpreter。前者提供了用于搭建 GUI 和配置界面的组件,也提供了开箱即用的<FusionXEditor />组件;后者提供了一系列 API 和<FuxRenderer />组件来在运行时根据 Schema 渲染应用程序。
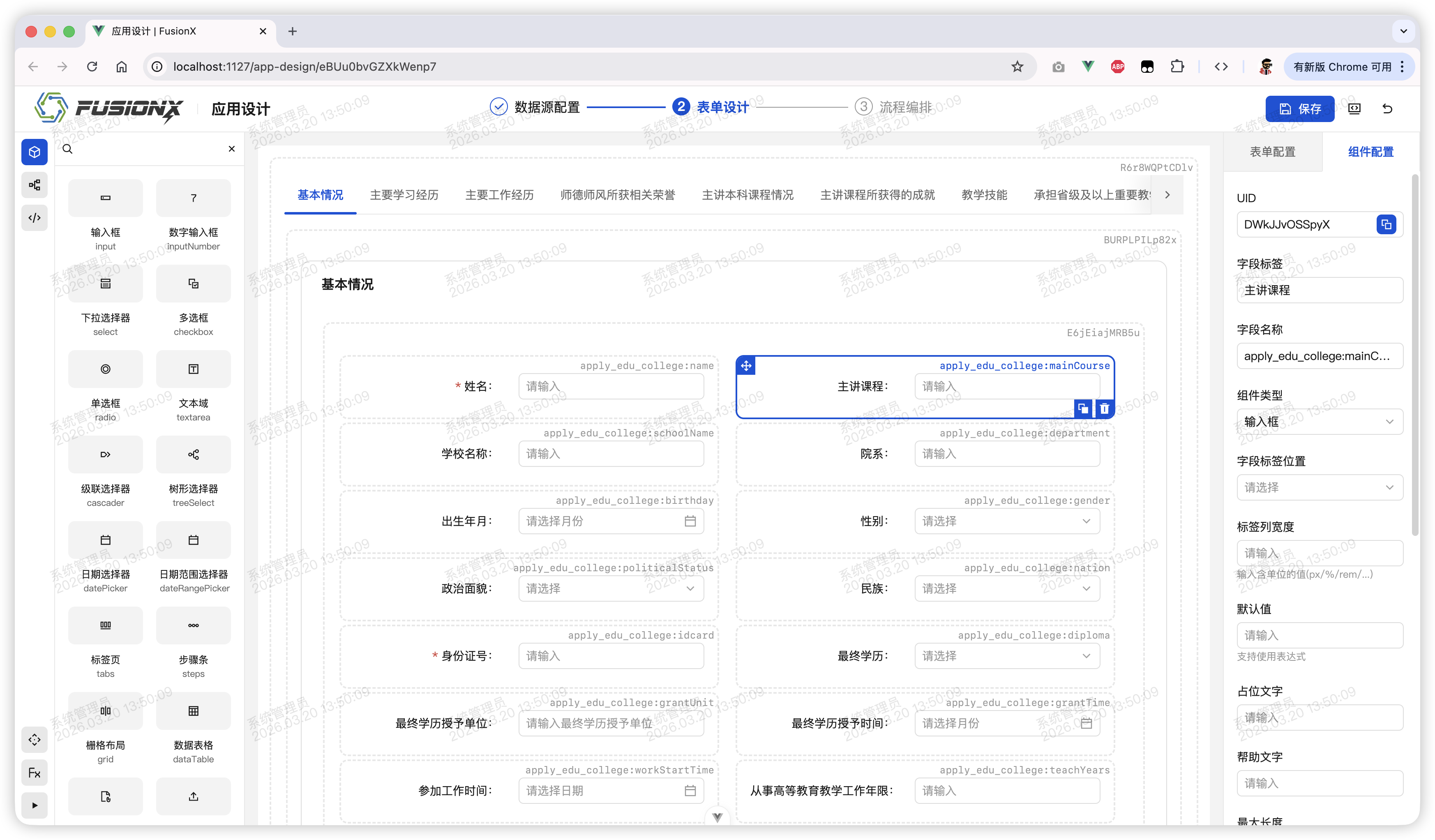
通过编辑器,开发者可以可视化构建应用程序。而应用程序中的组件及它们的属性、行为和相对位置等都被记录在了藉由编辑器生成的 Schema 中。这就是使用 FusionX 进行开发的核心。
Schema 的消费:AOT or JIT?
从 Schema 的消费角度讲,通常有两种形式:
- 静态编译(AOT),即在运行时之前,将 Schema 转换为浏览器可以执行的 JS、HTML 和 CSS。
- 动态编译(JIT),即在运行时,根据 Schema 动态生成 JS、HTML 和 CSS。
在设计之初,我们决定在 1.0.0 版本中优先实现动态编译。这主要是考虑到 FusionX 的首要任务是可以被立刻 drop in,替换现有的政务场景下服务表单的开发。这是一个典型的「流程+表单」的应用场景。这个场景的特点是其模式相对固定,属于页面的或业务的一个部分,且表单和流程的变更相对其他场景都更频繁。在采用静态编译的情况下,生成的代码无法再次被读取,一旦开发者对生成的代码进行了修改,再次发生变更时会覆盖修改的内容。
但是,静态编译也存在无法替代的优点,比如可以获得原生的性能表现、可以在编译阶段发现错误避免运行时的崩溃;对于修改频次低的业务,生成的代码可以由工程师已进行二次开发来满足 low code 下实现复杂的需求。当然,静态编译的形式也可以引入 linter 和 formatter 到编译链中对代码进行优化与检查。当开发包含完整生命周期的应用而非局限于表单部分时,静态编译是一个更好的选择。在最后我们会讨论 FusionX 2.0 的展望与规划,我们期望在 2.0 版本中可以实现完整的应用级别低代码开发,因此静态编译是必须要提上日程的。
构建 UI 无关的低代码引擎
当前我们所面临的一个现状就是各个团队都在使用不同的 UI 组件库,也有各自形成的可复用资产。当然,我们希望能在未来实现组织范围内的统一资产管理和维护体系,但是在现阶段,隔离的 UI 资产要求 FusionX 必须具备 UI 无关性。
不同的组件库之间,组件的类型,它们的属性名和可配置的值等都是不同的。例如在 Arco Design 中,有InputTag组件,而在 Ant Design 中则没有;在 Element Plus 中,Input没有无边框模式,但是在 TDesign 中则由borderless属性来控制。此外,各团队都有自行封装的组件,这些组件都各有其特殊属性。
好在,Schema 本身作为 JSON 结构是不依赖特定组件库的。关键在于让编辑器能够支持自定义组件的配置项、让编译器能够识别自定义的组件和属性并正确渲染。
在 FusionX 中,我们通过实现「入料」机制来解决这个问题。
「入料」
「入料」这个名词来自于阿里的Low Code Engine。在 FusionX 中,「入料」特指将不同的组件按照规则传入 FusionX 并被处理成可供编辑器和编译器使用的组件的过程。
首先来看一个简单的例子。FusionX 使用 TDesign 作为默认组件库,但假设有另一个MyInput组件,我们希望最终能够渲染和使用MyInput来代替 TDesign 中的TInput。这个时候,我们需要把MyInput入料。
入料的过程可以简单总结为:
- 指定如何渲染
MyInput组件。 - 指定可以如何配置
MyInput组件的属性和行为。
在 FusionX 中,每一个低代码组件基本都由运行时文件和配置时文件构成。可以看到@fusionx/core/internal/materials目录下,每一个组件目录中都有对应的setter.vue和index.vue,当然,部分表单组件还有阅读模式下的渲染文件view.vue,这种情况暂时不纳入讨论。
在进行自定义组件入料时,我们需要指定组件的渲染状态和配置状态。也就是说,对于每一个组件,需要创建两个组件分别告诉 FusionX 应当如何描述和渲染组件。
然后,在注册 FusionX 的时候,通过传入options.materials配置MyInput:
import FusionX from '@fusionx/core'
app.use(FusionX, {
materials: [
{
name: 'MyInput',
title: '自定义输入框',
group: 'form/basic',
main: () => import('@some-package/my-input/index.vue'),
setter: () => import('@some-package/my-input/setter.vue')
}
]
})
对于没有特殊配置逻辑的组件,一个更直接的方式是直接通过向setter属性传入用于渲染配置项的 JS 对象。支持的属性包括:
export interface SetterMeta {
/** Props of the material that can be config in the setter. */
props: Array<{
/** Setter type. */
type: 'input' | 'select' | 'switch' | 'number' | 'code'
/** Setter label. */
label?: string
/** Setter name. Corresponds to the property name of the material. */
name?: string
/** Setter props. e.g. `options` for `select` type; `min`, `max` for `number` type. */
setterProps?: Record<string, unknown>
defaultValue?: unknown
/** Whether the setter value can be bound to a state/expression. */
allowBinding?: boolean
/**
* Whether the setter should be rendered.
* e.g. The `max` prop setter of the select widget should not be rendered when the `multiple` prop is `false`
* @param props The props of the material.
* @returns Whether the setter should be rendered.
*/
shouldRender?: (props: Record<string, unknown>) => boolean
}>
/** Additional config of the material. */
config: {
supports?: {
/** Supported event names of the material. */
events?: string[]
}
}
}
在大多数情况下,入料的组件可配置项完全可以用SetterMeta的结构来描述。只有对于部分组件,配置面板中具有特殊逻辑时(例如Tabs组件中,有定义标签页的功能)才推荐向setter传入一个用于配置的 Vue 组件。讲到这大家就应该知道了,SetterMeta本身也像是 Schema,配置面板的实现其实也是引用了 FusionX 中的编译或者说渲染的逻辑。
灵活性策略:与 pro code 集成
FusionX 的研发过程得到了各个项目团队的鼎力支持,我们的人手也抽调自各团队。但即便如此,FusionX 也无法保证 100% 覆盖所有可以使用 pro code 研发的场景。针对我们业务中复杂的需求,我们一方面要考虑如何在 FusionX 中以一种相对简化的、无需专业前端工程师也能实现的方式呈现,另一方面也要考虑如何在 pro code 的开发环境中使用 FusionX 提供的能力。
编辑器内能力
首先,在 FusionX 中,我们提供了数据源和函数。这是两个强大的功能,分别用于从外部获取数据和在应用中执行自定义逻辑。
FusionX 编辑器中,数据源会在特定的时刻执行,其返回值可以被绑定到组件的属性上;而函数则可以被绑定到组件的事件、应用的生命周期或者表单的校验上。对于常见的需求:比如「根据用户输入的两个时间自动计算差值」「如果 A 的值超过某个数时就不显示 B」「如果 C 的值变更,那么下拉选单 D 的选项会被替换为另一个数组」等,均可以通过数据源、函数或两者的搭配实现。
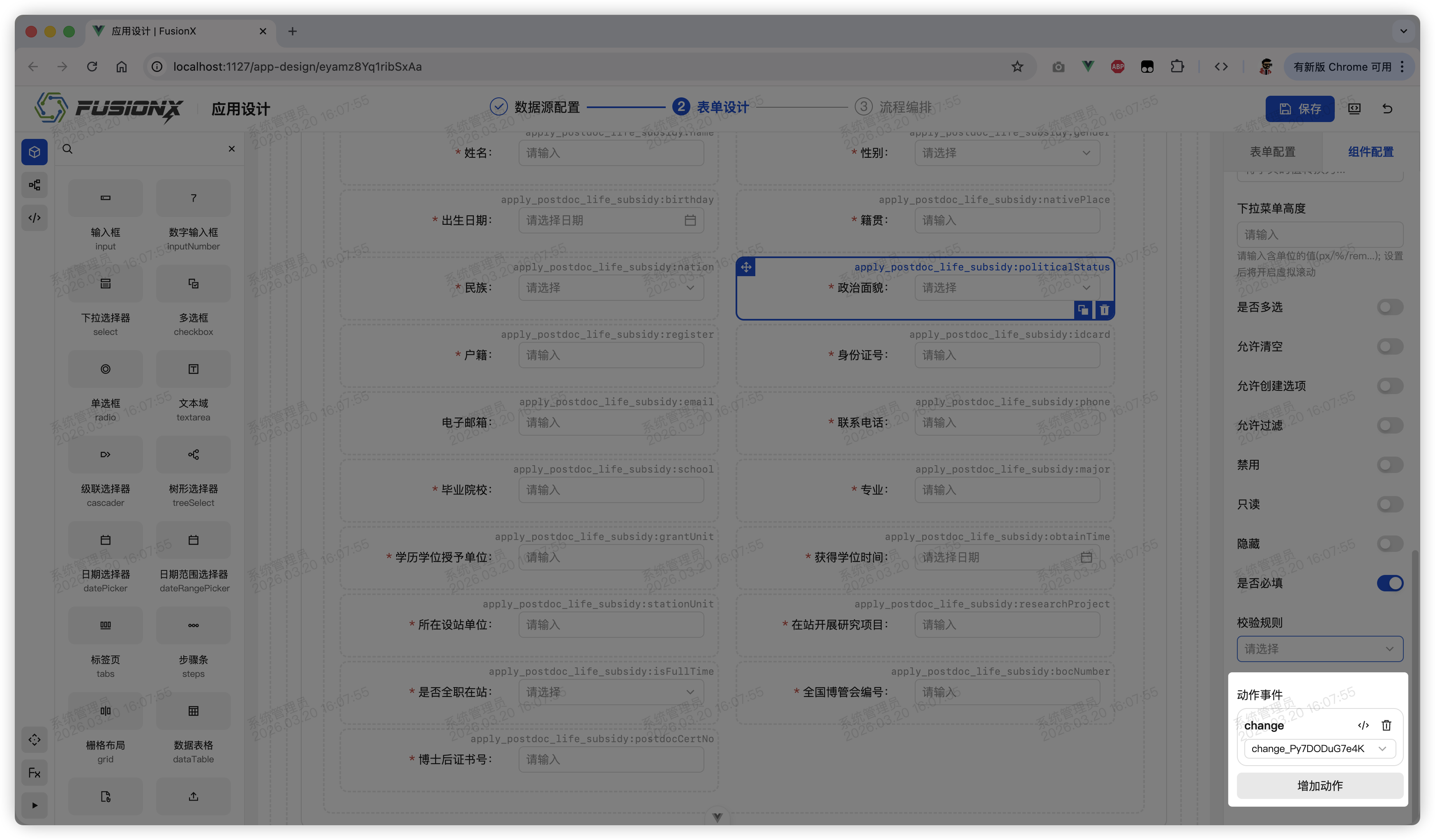
在函数中,FusionX 向开发者暴露了部分 API,用于在函数中访问和操作组件和应用的状态。下面的图展示了其中的部分:
$values:获取表单中所有组件的值。$state:获取数据源的状态值。$dayjs:同全局的dayjs函数。$mode:当前应用渲染的模式,往往用于在不同渲染环境下行为不一致的逻辑(例如事项办理与事项审核两个状态)。$refs:获取所有设置了引用的组件的引用。可以通过$refs.<组件引用>.来调用部分组件暴露的方法。
组件
对于需要在业务中部分使用 FusionX 进行渲染的场景,调用 FusionX 提供的组件以及它们的实例方法也可以实现一些特殊需求。例如,对于呼声很高的申报列表开发,我们就可以通过引入 FusionX 提供的<ApplyList />并传入appId来快速实现一个带有筛选表单、可配置列、分页且可以正常与业务的低代码部分交互的列表;再比如,有项目团队曾经希望避免调用 FusionX 内部表单组件的提交,而是先获取到数据,这可以通过<FuxRenderer />的ref.$refs.<表单组件>.getFormData()方法实现。
通过结合两个与 pro code 的集成维度所提供的能力,目前来说 FusionX 足以满足大部分场景的需求。
面向未来:FusionX 2.0
在 FusionX 发布第一个版本时,我和团队成员都有非常多的想法。其中一部分无疑是关于 FusionX 如何演变来支撑后续的业务发展。今天的最后我想分享一下,如果资源允许的情况下,FusionX 2.0 会带来哪些变化。
重构
经过一段时间的使用,也包括项目团队对各业务项目使用 FusionX 开发的过程的「视奸」,有些问题得以被迅速暴露出来。我们希望在 2.0 能够重构这些部分,其中包括大家已经提出来的函数编辑器的性能问题等。
下图展示了我们预计重构的部分功能点。我们也希望在现阶段,各位能积极为我们提供反馈意见。
但其实,说到重构,在 FusionX 第一个版本为期半年的开发过程中,前端进行了两次重构。我不会深入设计模式和整洁代码这类技术细节来探讨重构的内容和最终成果。但我们要问一个问题:为什么要在开发时重构?
很简单,因为我们不会在“重构时”重构。我们平常经常说的“先这样吧,有空再改”是一句彻头彻尾的谎话。根本不会有单独的时间用于重构——在项目中时间紧迫,我们会抱有侥幸,认为时间这么紧张,不是重构的时机;而当项目的冲刺期过去,我们会想已经过去的事情不必再次提起,因而就让往事随风而去。所以,永远不会有重构的时机。
有的同事可能会说:“可是我真的很忙”!
相信我,我也是,我们都是。但时间紧张并不是进行妥协的借口,因为进行妥协并不能够真的缩短工期。即便可以,面对几乎 100% 需要调整的需求,所节约的时间将在日后的修改和维护中因为技术债务的存在而加倍偿还。我们作为专业的技术人员,不能够因为妥协而丧失我们的专业性。
静态编译
我们要在 2.0 为大家带来的一个重磅更新就是对静态编译的支持。这个在刚才已经讲到过,静态编译是通往应用级低代码开发的基石,毕竟我们不可能整个系统全部建立在动态渲染的 JIT 机制上,那样不仅性能会受到影响,视觉上因动态加载和渲染导致的 CLS 也会增加。
插件与生态
在 FusionX 2.0 中,我们将支持插件机制,允许开发者为 FusionX 开发插件。从技术角度说,插件是一个 JS 对象,可以在注册 FusionX 的时候传入。插件本身由一系列生命周期钩子构成,因此可以在不同的时候执行不同的逻辑。
在目前的版本中,我们已经在为这一点进行尝试。例如 FusionX 暴露的 API,届时都可以被插件调用;插件作用的场景和生命周期也已经被明确。具体来说,一个 FusionX 插件可以在编辑器中作用,也可以在运行时生效;可以在编译过程中对 Schema 进行转换,也可以在用户提交表单时拦截数据。
在 FusionX 2.0 发布时,也会内置一个插件用于演示插件能力。这个插件会在 FusionX 编辑态自动加载,以树状形式展示当前页面上的组件树结构,以及每一个节点依赖的数据状态。
最后
从编程的角度来说,Schema 也像是我们自己的「语言」,编写这种语言的过程就是通过 FusionX 进行开发的过程。同样地,执行这种「语言」,也需要能够把语言转换成浏览器可以执行的 JS、HTML 和 CSS。在上面展示的 FusionX 的构成图中,其实就是一个「使用开发环境编写了编程语言,然后由解释器将其转换成可执行程序」的过程。
如果再进一步想,在计算机领域,最初的编程是通过汇编语言进行的。后来,人们采用高级语言编程。现在,人们可以使用低代码工具进行编程,刚才我们说到 Schema 其实就相当于编程语言。可以预见的未来,人们还会通过向 AI 智能体发出指令的方式来编程,那么自然语言其实也可以被看做编程语言。
编程这个活动所使用的语言、开发工具和环境在发生演变,但编程作为一项活动不会消失。就像会计师始终存在,只不过所用的工具由算盘、计算器变成了计算机、财务一体化软件和 AI 智能体。作为工程师的我们,应当拥抱新的概念,并且——如果它有利于实现降本增效和为角色赋能的目标——积极地应用它、塑造它。